Faster RCNN
简介
\(Faster \: RCNN\)主要包含:
- \(Head\: (CNN)\).
- \(Region\: Proposal\: Network\: (RPN)\).
- \(RoI \: Pooling\).
- \(Classification\: Network\).
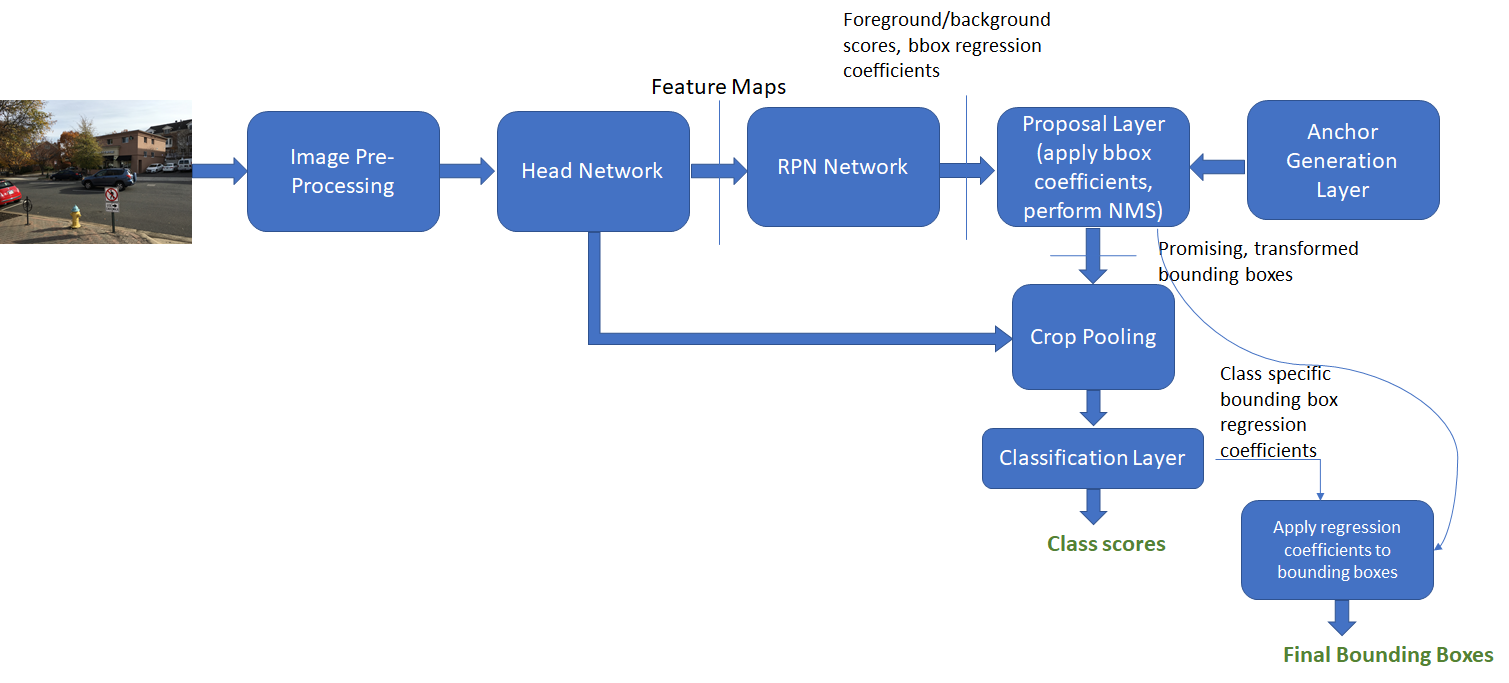
在介绍\(Region \: Proposal\: Network\)之前,先了解下\(Anchor\):
1. Anchor是什么?它的作用是什么?目标检测不同于分类,不仅需要输出物体的类别,还需要定位物体的位置。训练过程是对损失函数优化求解过程,损失函数需要真实值(Ground Truth GT)与预测值(Prediction)构造,目标检测中GT由物体真实class+bbox组成,关键是相应的bbox_pred如何得到?构造。就像神经网络中权重最开始是随机初始化,前向得到不准确的值,再反馈调整权重使得预测值逼近真实值。同样的,我们先生成很多个框(Anchor),再后续进行调整。
2. Anchor如何构造,需要考虑什么因素?- 大小(scale)。 比如桌子上的杯子,桌子与杯子的面积大小不一。
- 长宽比(ratio)。比如人脸与行人的长宽比例是不一样的。
- 位置(Location)。除了框的形状,还需要空间位置信息,即Anchor的坐标。
本文内容:
- Anchor Generation Layer: 生成Anchor
- RPN Network: Featutre Maps经过该层得到Anchor的前景/背景概率,以及类别信息
- Proposal Layer: 筛选Anchor
- RoI Pooling: 对feature变换为统一长度输入到FC层。
1. Generate Anchor
只考虑scale和ratio。假设原图\(400×400\)。我们选取三种长宽比[2, 1, 0.5],三种scale[0.5,0.25,0.125],得到\(9\)个不同的anchor.
| scale\ratio | 2:1 | 1:1 | 1:2 |
|---|---|---|---|
| \(200×200(\frac{1}{2})\) | \(282.8×141.4\) | \(200×200\) | \(141.4 × 282.8\) |
| \(100×100(\frac{1}{4})\) | \(141.4×70.7\) | \(100×100\) | \(70.7×141.4\) |
| \(50×50(\frac{1}{8})\) | \(70.7×35.3\) | \(50×50\) | \(35.3×70.7\) |
 计算过程如下:
计算过程如下:
① 计算anchor的长宽 \(w = 400 * scale , h = 400 * scale\)
② anchor面积 \(s = w * h\)
③ 根据ratio计算anchor长宽 \(w = \sqrt{\frac{s}{ratio}}, h= \sqrt{s*ration} \quad (\frac{h}{w}=ratio)\)
④ 以原点为中心计算对角顶点坐标。 \(x_1, y_1 = - \frac{w}{2}, - \frac{h}{2}; x_2, y_2 = \frac{w}{2}, \frac{h}{2}\)
考虑位置。这9个anchor放在图片的哪些位置?我们并不知道,那么就遍历整张图片,将每个像素点作为中心点生成9个anchor,如下左图,黑色边框为原图。这样生成的anchor就足以覆盖整张图片(下右图)。 


长宽比scale\((0.5, 1, 2)\)
面积大小\((8*8, 16*16, 32*32)\)
输入图片大小为\(800*600\)
stride=16的意思是每隔16个点取一个点生成9个anchor,那么则有\(\frac{800}{16}*\frac{600}{16}*9 = 1900*9\)个anchor。计算过程也很简单,首次计算9个anchor的顶点坐标后,取下一个点直接将9个anchor的对应坐标平移一位即可,一直重复向右向下平移即可得到上右图红色框。
2. Region Proposal Network

2.1 anchor分类为前景和背景
① feature map\((W×H)\)经过3×3卷积大小不变,因为padding=1,相当于长宽都扩充了2个像素。
② 再经过1×1的卷积核(channel=18)变为\(W×H×18\)
③ reshape成\((W×H×9, 2),W×H×9\)表示anchor数量,2表示前景/背景。
④ softmax得到最终每个anchor的二分类概率。
2.2 Bbox Regression
同样的,bbox的shape为\((M×N×9,4)\),表示每个anchor的左上顶点与长宽\((x_a, y_a, w_a, h_a)\)。那么这里的损失函数如何构造?预测的anchor如何与ground truth的boxes联系起来?
\[t_x = \frac{x_a - x}{w_a}\quad t_y = \frac{y_a - y}{h_a}\] \[t_w = \log(\frac{w}{w_a}) \quad t_h=\log(\frac{h}{h_a})\]回归系数\((t_x, t_y, t_w, t_h)\)表示bbox的平移量和缩放量。如果用回归系数的绝对值作为损失函数即为\(L_1\)损失,但是这样在零点处不可导,且梯度在训练过程中一直不变,导致再后期很难收敛。
\[L_1 = |x| \qquad \frac{d L_1}{dx}=\left\{\begin{matrix} 1,\quad x\geq 0\\ -1, \quad otherwise \end{matrix}\right.\]而\(L_2\)损失在随着\(x\)的变化更新梯度,但是在训练前期差异很大时,梯度也很大训练不稳定。
\[L_2 = x^2 \qquad \frac{d L_2}{dx}=2x\]\(smooth_{L_1}\)损失则考虑:(1)当预测值与真实值差别很大时,梯度不至于过大。(2)当预测值与真实值差别很小时,梯度足够小。
\[smooth_{L_1} = \left\{\begin{matrix} 0.5 x^2, \quad |x|<1\\ |x|-0.5, \quad otherwise \end{matrix}\right. \qquad \frac{d\,smooth_{L_1}}{dx}=\left\{\begin{matrix} x, \quad |x|<1\\ \pm 1 , \quad |x|>1 \end{matrix}\right.\]2.3 Anchor Target Layer
在计算损失时,并不是将所有的Anchor都拿去计算。举个例子,班级中学生成绩参差不齐,老师的目标不是让每个学生都上清华北大,而是选出一批潜力大的学生来培养即可。对于“差生”来说这个目标不太实际,同样的将差异悬殊的Anchor与Ground Truth进行BBox训练回归也是无效任务。
那么,“优等生”与“差生”需要一个评价标准:IoU(Intersection of Union)。IoU用来衡量两个区域交叉重叠的程度。Anchor与Ground Truth的交叉区域大于前景阈值(RPN_POSITIVE_OVERLAP)时,将其标为前景(foreground),小于背景阈值(RPN_NEGATIVE_OVERLAP)标为背景(background),忽略既不是前景也不是背景的anchor。
将选出来的Anchor计算损失训练RPN Network。注:Bounding Box Loss只用前景的Anchor计算,因为Gound Truth只有前景物体。
3. Proposal Layer

3. ROI Pooling
ROI Pooling是在SPPNet对RCNN的改进。将feature map中对应ROI区域扣出来,即原图ROI在feature map上位置的映射,再划分网格统一大小输入到FC层。
Enjoy Reading This Article?
Here are some more articles you might like to read next: