|
|
|
|
|
|
|
|
|
|
|
|
|
|
MAIS, Institute of Automation, Chinese Academy of Sciences, Beijing, China2 Max Planck Institute for Intelligent Systems, Tübingen, Germany3 OPPO Research4 Westlake University5 Tencent AI Lab6 CAIR, HKISI, CAS7 |
|
|
|
|
|
|
 |
T. Liao, X. Zhang, Y. Xiu.
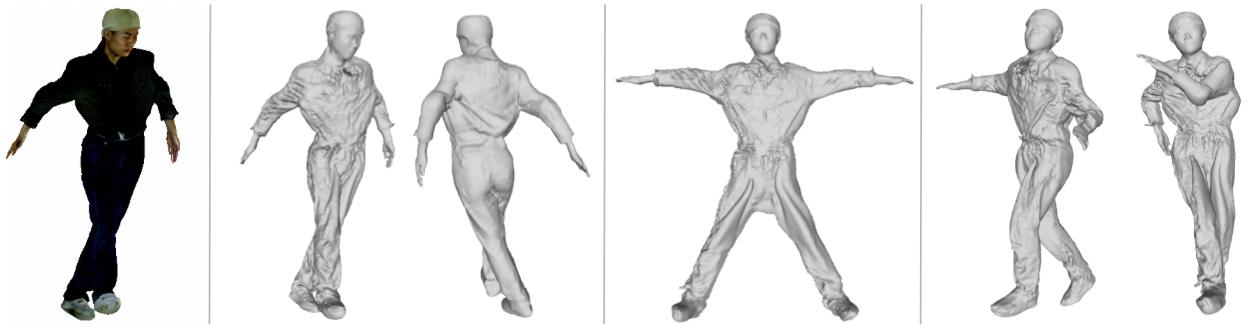
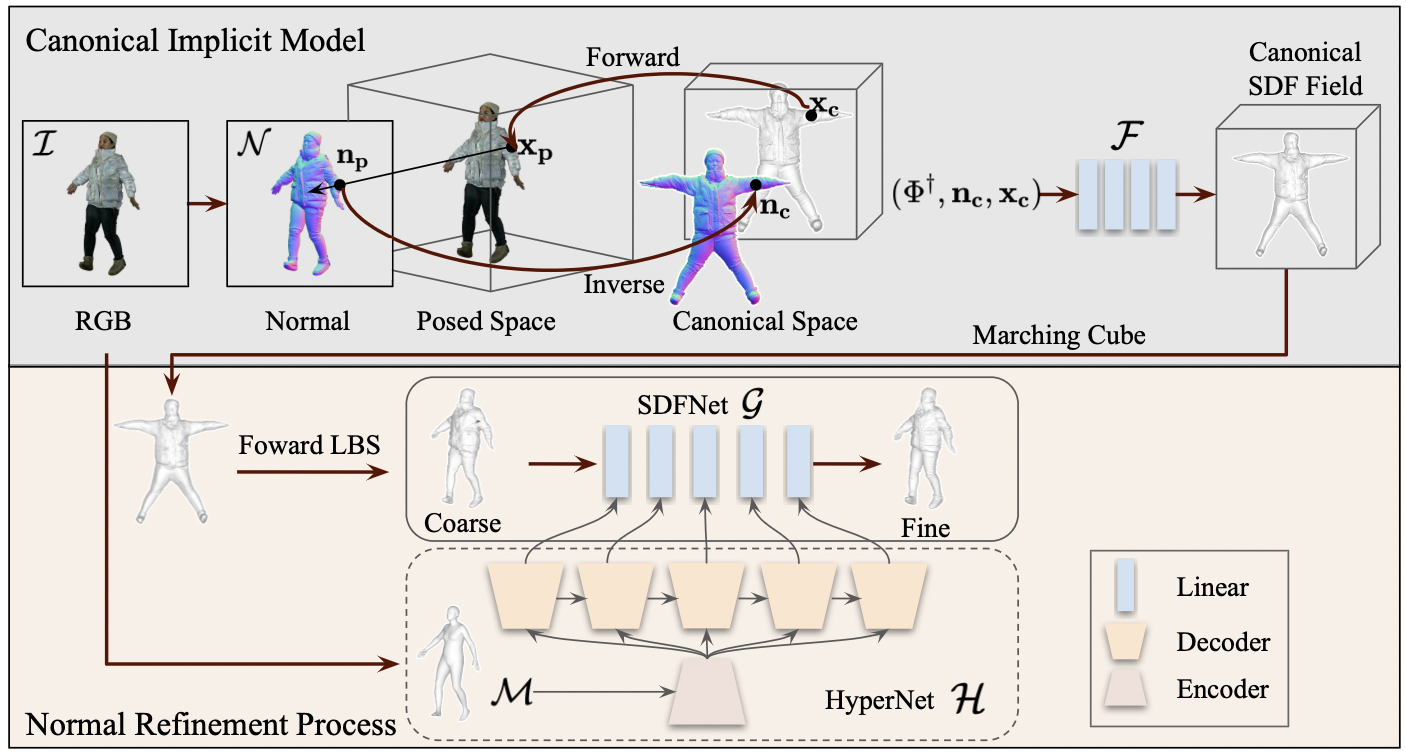
High-Fidelity Clothed Avatar Reconstruction from a Single Image. In CVPR, 2023. [ArXiv] [Bibtex] |
Acknowledgements |